Notes
- Permalink
DeepSeek Sparse Attention, some considerations about it after reading the paper.
DeepSeek-V3.2-Exp is defined as an experimental sparse-attention model. Its architecture is the same as DeepSeek-V3.1-Terminus, except for the introduction of DeepSeek Sparse Attention (DSA). The core idea is to reduce the number of key-value pairs each query token looks at, instead of attending to all tokens. Sparse attention only computes a subset of entries, making long-context reasoning more feasible.
Most sparse methods fix a pattern, but DSA is dynamic. It is composed by (i) a lightning indexer that computes a lightweight index score between query and candidate tokens, and selects the top-k most relevant tokens per query; (ii) a fine-grained token seelction mechanism that retrieves only the key-value entries corresponding to the top-k index score. From what I can understand, each query chooses its own set of tokens. The main advantage is that it’s more adaptive, because it’s based on a query-specific selection rather than fixed pattern. But this introduces the need of an extra module (the indexer) and its own training. Also, some performance drops in reasoning-heavy tasks if too few tokens are selected, but this small aspect is negligible in the whole context. I think that this suggests that DSA prunes aggressively but sometimes removes “useful but not obviously important” context tokens.
More about the lightning indexer: it is implemented with few heads and even in FP8. I think it’s a smart design choice. It’s lightweight enough not to negate efficiency gains, and it offers adaptive sparsity.
My takeaway for now is that hybridization is the practical path, in my opinion it is unavoidable. We’ve seen Qwen-Next models using hybrid layers, and I really like that solution, the models perform pretty well. Nevertheless, I like DSA and I think it’s compelling because it can be introduced via continued training, meaning the model doesn’t lose what it already learned under dense attention.
- Permalink
Qwen3-Max has been released from Qwen team. It’s their largest and most advanced large language model to date. It competes against GPT-5 and Grok 4.
The base model has over 1 trillion parameters and was pretrained on 36 trillion tokens. Its architecture seems to follow the same of other models from Qwen3 series: it provides a highly optimized MoE design, which activates only a subset of parameters per inference. This is something we’ve already seen with Qwen3-Next models, form which I think it inherits the same context window also.
The thinking variant, Qwen3-Max-Thinking, it is equipped with tool use and they say it’s deployed in heavy mode. It’s unclear to me what do they mean with it: perhaps they give it way more computational resources compared to the non-thinking variant.
They are taking the core architecture and maxxioptimizing it to reduce costs and improve efficiency. It’s impressive to me.
In the last 12 hours, Qwen has released:
- Qwen3-Max
- Qwen3-VL-235B-A22B: most powerful vision-language model in the series
- Upgrade to Qwen3-Coder: improved terminal tasks, safer code gen
- Qwen3Guard: safety moderation series for real-time AI content filtering
- Personal AI Travel Designer: new feature in Qwen Chat for personalized trip planning
- Qwen3-LiveTranslate-Flash: low-latency live translation model for real-time audio/text
While Qwen is continuing to optimize and release new models, I’ll wait for DeepSeek. I’m convinced they are cooking.
- Permalink
Go has added Valgrind support. While reading the commit, I saw this:
Instead of adding the Valgrind headers to the tree, and using cgo to call the various Valgrind client request macros, we just add an assembly function which emits the necessary instructions to trigger client requests.
This is super interesting. Let’s have a quick look at the code:
// Copyright 2025 The Go Authors. All rights reserved. // Use of this source code is governed by a BSD-style // license that can be found in the LICENSE file. //go:build valgrind && linux #include "textflag.h" // Instead of using cgo and using the Valgrind macros, we just emit the special client request // assembly ourselves. The client request mechanism is basically the same across all architectures, // with the notable difference being the special preamble that lets Valgrind know we want to do // a client request. // // The form of the VALGRIND_DO_CLIENT_REQUEST macro assembly can be found in the valgrind/valgrind.h // header file [0]. // // [0] https://sourceware.org/git/?p=valgrind.git;a=blob;f=include/valgrind.h.in;h=f1710924aa7372e7b7e2abfbf7366a2286e33d2d;hb=HEAD // func valgrindClientRequest(uintptr, uintptr, uintptr, uintptr, uintptr, uintptr) (ret uintptr) TEXT runtime·valgrindClientRequest(SB), NOSPLIT, $0-56 // Load the address of the first of the (contiguous) arguments into AX. LEAQ args+0(FP), AX // Zero DX, since some requests may not populate it. XORL DX, DX // Emit the special preabmle. ROLQ $3, DI; ROLQ $13, DI ROLQ $61, DI; ROLQ $51, DI // "Execute" the client request. XCHGQ BX, BX // Copy the result out of DX. MOVQ DX, ret+48(FP) RETThis is the amd64 assembly for the Valgrind client request. This asm emits the exact instruction sequence that Valgrind’s macro
VALGRIND_DO_CLIENT_REQUESTwould have produced in C, just without cgo.On arm64, the same idea is implemented with different registers and the AArch64 “marker” Valgrind looks for.
It’s nice because they do everything on the language itself, even when relying on assembly. Some reasons I could imagine they do it this way: to avoid cgo and keep the runtime pure-Go, but most importantly control.
Really interesting for me that Go team decided to follow this route. Also, I’m not a fan of cgo.
- Permalink
New model in town! GPT-5-Codex is a version of GPT-5 specifically realized for agentic coding in Codex. Here’s what you need to know:
- It dynamically adapts its thinking based on the complexity of the task.
- Adheres to AGENTS.md instructions.
- It has been trained specifically for conducting code reviews and finding critical flaws.
- GPT-5 and GPT-5-Codex achieve comparable accuracy on SWE-bench Verified (72.8% vs. 74.5%), but GPT-5-Codex shows a clear advantage in code refactoring tasks (51.3% vs. 33.9%).
- OpenAI found that comments by GPT‑5-Codex are less likely to be incorrect or unimportant: GPT-5-Codex produces fewer incorrect comments (4.4% vs. 13.7%) and more high-impact comments (52.4% vs. 39.4%) than GPT-5. Interestingly, GPT-5 makes more comments per pull request on average (1.32 vs. 0.93), but with lower precision and impact.
Many are complaining about the naming and the “Codex everywhere”. Honestly, I don’t care so much about the poor naming scheme as long as models and tools are good.
GPT-5-Codex is not available in the API but it will be soon. To use it, you will need Codex CLI, so make sure to install it:
npm i -g @openai/codex. @sama claims that GPT-5-Codex already represents ~40% of traffic for Codex.I installed and tried it (yes, haven’t done before, this is the first time for me using Codex). You can choose the model reasoning effort: prompting
/model, Codex will let you choose betweengpt-5-codex low,gpt-5-codex mediumandgpt-5-codex high. Although OpenAI recommends to leave the model_reasoning_effort at default (medium) to take the most advantage of the more dynamic reasoning effort.Along with the model, they also provided more updates:
- Codex runs in a sandboxed environment with network access (opens in a new window) disabled, whether locally or in the cloud.
- In Codex CLI, you can now resume a previous interactive session.
- Once turned on for a GitHub repo, Codex automatically reviews PRs.
- It is possible to asynchronously delegate tasks to Codex Cloud.
And more.
I think they’re heading in the right direction, actually. They’re focusing their efforts on the tools, which is good. What’s more, I have to say that I’ve reevaluated GPT5 and am using it daily instead of Claude. That’s why I appreciate and welcome these new releases.
Last but not least, Codex is open-source!
- Permalink
Qwen team released two new models: Qwen3-Next-80B-A3B-Instruct and Qwen3-Next-80B-A3B-Thinking. Both are already present on HuggingFace. Qwen also published a post on their blog.
Compared to the MoE structure of Qwen3, Qwen3-Next introduces several key improvements: a hybrid attention mechanism, a highly sparse Mixture-of-Experts (MoE) structure, training-stability-friendly optimizations, and a multi-token prediction mechanism for faster inference.
Both models are based on the Qwen3-Next-80B-A3B-Base model, which only activates 3 billion parameters per token. Qwen 3 Next is an ultra-sparse MoE with 512 experts, combining 10 routed experts and 1 shared experts. Also, it’s based on a hybrid architecture, composed by Gated DeltaNet + Gated Attention.
They say Qwen3-Next-80B-A3B-Instruct approaches their 235B flagship, and Qwen3-Next-80B-A3B-Thinking seems to outperform Gemini-2.5-Flash-Thinking.
Qwen 3 Next natively supports context lengths of up to 262,144 tokens, but they even validated it on context lengths of up to 1 million tokens using the YaRN method. YaRN is supported by
transformers,vllmandsglang. - Permalink
Apple presented the iPhone Air, the thinnest iPhone ever. This is the only new release from Apple that got my interest during their presentation event.
Its design is interesting: the entire logic board and A19 Pro chip are compacted into the camera bump (which includes both front and rear cameras). This iPhone is all battery and screen. IMHO, it seems like a strategic move for the coming years, for which this iPhone Air will serve as an experiment or a launchpad for ultra-thin devices, or simply as a research and development testbed for similar designs that enable powerful yet ultra-compact technologies.
Remarkable factor, iPhone Air has A19 Pro, which is Apple’s latest SoC. More in detail: it is built on TSMC’s N3P process node, and benefits from a 20% increase in transistor density compared to its predecessor, the N3E node, according to a 2023 IEEE study on semiconductor scaling. The A19 Pro features a six-core CPU with two high-performance cores and four efficiency cores, and 5-core GPU. Each GPU core has its own Neural Accelerators, which Apple claimed allows for MacBook Pro-level performance in an iPhone. On the new iPhone Pro, they are even more powerful. If the M5 chip will get this GPU upgrade… well, NVIDIA should start to feel some pressure.
To summarize: local AI to the Max. Next year, I want local LLMs on my phone.
- Permalink
Yesterday, a lot of npm packages have been compromised with malicious code. Following, a list of affected packages:
- ansi-styles@6.2.2
- debug@4.4.2 (appears to have been yanked as of 8 Sep 18:09 CEST)
- chalk@5.6.1
- supports-color@10.2.1
- strip-ansi@7.1.1
- ansi-regex@6.2.1
- wrap-ansi@9.0.1
- color-convert@3.1.1
- color-name@2.0.1
- is-arrayish@0.3.3
- slice-ansi@7.1.1
- color@5.0.1
- color-string@2.1.1
- simple-swizzle@0.2.3
- supports-hyperlinks@4.1.1
- has-ansi@6.0.1
- chalk-template@1.1.1
- backslash@0.2.1
and more, I think. I suggest to read the original post published on aikido.dev[1] and related HN discussion[2], both links are reported below.
All packages appear to contain a piece of code that would be executed on the client of a website, which silently intercepts crypto and web3 activity in the browser, manipulates wallet interactions, and rewrites payment destinations so that funds and approvals are redirected to attacker-controlled accounts without any obvious signs to the user (as shared from Aikido).
You can run grep or rg to check if your codebase has been impacted – thanks to sindresorhus for this suggestion:
rg -u --max-columns=80 _0x112fa8This one requires ripgrep, but you can do the same with
grep(ripgrep its Rust equivalent redesign).My thoughts about this: dependency hell is real and these are the results. I agree with Mitchell Hashimoto when he says that npm should adopt some strategies to mitigate these risks, such as rejecting all dependencies tha have less than 1k LoC. I mean, let’s just avoid using external packages to determine if an object can act like an array.
Also, I would like to share one insight reported by DDerTyp on HN:
One of the most insidious parts of this malware’s payload, which isn’t getting enough attention, is how it chooses the replacement wallet address. It doesn’t just pick one at random from its list. It actually calculates the Levenshtein distance between the legitimate address and every address in its own list. It then selects the attacker’s address that is visually most similar to the original one. This is a brilliant piece of social engineering baked right into the code. It’s designed to specifically defeat the common security habit of only checking the first and last few characters of an address before confirming a transaction.
Needs a little bit of more investigation, for which I don’t have enough time, but looks interesting.
[1] Original post
- Permalink
Yesterday, Fil-C popped up to the top of Hacker News. This time the submission got a fair amount of traction, sparking a lot of interest in the community, including a comment from Andrew Kelley. In fact, I’ve been interested in Fil-C for about a year already: my first submission on Hacker News was eight months ago. So I can say I’ve been actively following the project’s progress, also thanks to the activity of its creator, @filpizlo, on Twitter.
Fil-C is a compiler that implements the C and C++ languages with a memory-safe approach. Recently, Filip has published more documentation about the Garbage Collector and about the capabilities he calls “InvisiCaps”, which are more related to pointer safety.
Well, for me this is kind of a dream. I love the C language, it’s my favorite, but I admit I have some skill issues when it comes to memory management, though not because of the language itself, but rather due to my own code-writing proficiency, which could definitely be better. Recently, I’ve been exploring Rust and Zig precisely for this reason, and I’ve found myself appreciating Zig more than Rust because of its minimalism. Having a memory-safe implementation of C would therefore resolve a lot of the headaches caused by memory management.
Fil-C seems like the sweet spot between academic research and pragmatic work. Beyond the documentation, there’s also a list of programs already ported to Fil-C, showing that sometimes no code changes are required, and when they are, the effort is moderate.
So, the next step for me is to dig deeper into the topic and try it out myself! In the meantime, I thought it would be fair to personally share what Filip is doing, because the project deserves much more attention than it’s currently getting, imo.
- Permalink
There is a very interesting law that I think is worth sharing:
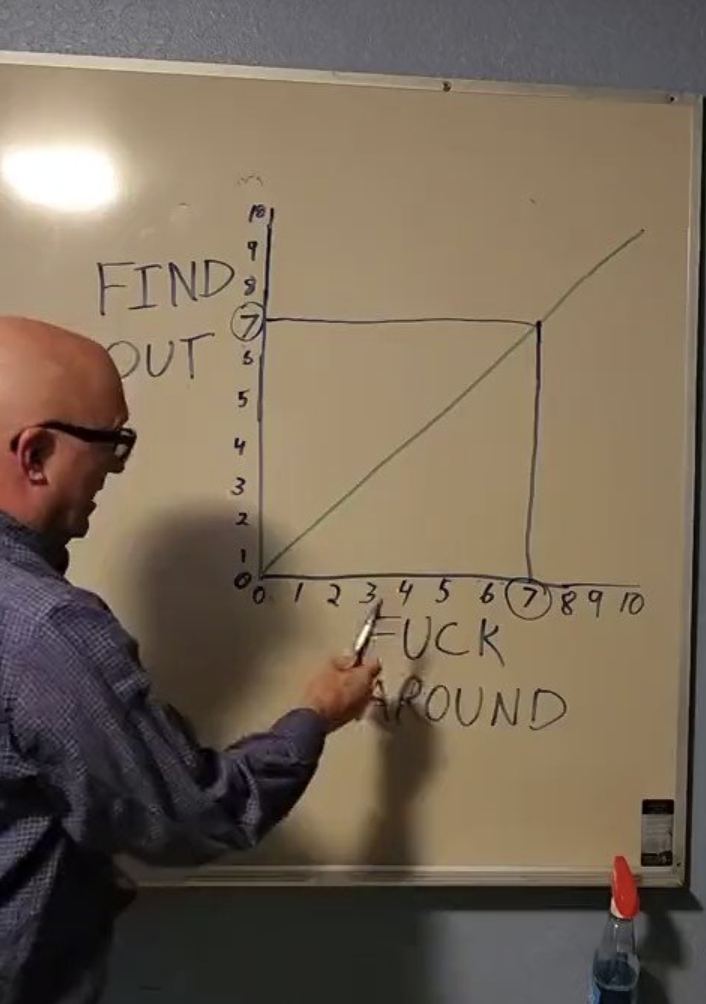
I will apply it more often.
- Permalink
I’m Sicilian, and I support building the Strait of Messina Bridge.
Premise: I don’t vote for Matteo Salvini, the current Minister of Infrastructure and Transport and promoter of the project. Even though, to be fair, many before him have tried to start construction on the Bridge, since it’s been discussed ever since the post-World War II era. In modern times, both Silvio Berlusconi and Matteo Renzi (two politicians from opposing sides) have pushed the idea. So my support doesn’t come from political or ideological alignment, but from a pragmatic standpoint.
I’m in favor of building the Bridge because I’m in favor of progress. We’re talking about a world-class engineering project: a suspension bridge with a single span of 3,300 meters (over two miles), the longest in the world. Naturally, it will bring together some of the brightest minds to contribute to its construction. We’re daring to attempt something unprecedented and structurally thrilling, and we’re doing it between two Italian regions, Sicily and Calabria, that have historically been intellectual and cultural cradles not only for Italy, but for the entire world. That excites me.
It’s also an investment currently estimated at 13 billion euros. With projects of this scale, I doubt the final figure will really stay there, because you have to factor in circumstances and unforeseen events. So, to that number, you can probably add another 17 or 18 billion euros. On paper, it has all the potential to generate new jobs and opportunities, both for companies in the sector and beyond.
A bridge means greater connectivity and logistical efficiency. Right now, traveling from Sicily to Calabria happens via ferry, something that has become an icon for us Sicilians. Yes, this system could be improved and strengthened. But it’s also true that it still represents an obstacle to the continuous flow of rail traffic between regions. That problem could be solved with the Bridge, which, according to the plan, will have two highway lanes and, in the middle, two railway tracks. This would allow high-speed trains to reach Sicily.
These are some of the advantages that lead me to support the construction of the bridge, regardless of my political ideology, which has no influence on my opinion here. But what are the counterarguments from the public? Below the ones I read most often, with some of my thoughts.
Seismic risk: according to the plan, the bridge will have to withstand earthquakes up to a certain level on the Richter scale. I expect the design to largely incorporate structural and tolerance systems for such events.
Environmental impact: this factor would definitely need to be monitored, even though it has been overlooked in the construction of other major public works, not only in Italy but around the world. Speaking from ignorance, I imagine the terrain will need to be modified for the creation of the towers’ supporting foundations. I expect this to be done in compliance with existing environmental risk regulations.
High costs: this is undeniably a very expensive project. What’s often not taken into account, however, are the long-term returns and the economic flow generated by indirect effects: creation of new businesses, jobs, and so on.
I’m genuinely enthusiastic about the project. Above all, the concept of “connection” fascinates me and sparks my imagination.
- Permalink
I have been working with Helm for some time now and I’ve developed a love-hate relationship with it. It seems to have become the de-facto package manager for K8s, and there are good reasons for that. But like any tool, it comes with its own set of frustrations that can make you question your life choices. Some honest thoughts follow.
What I like
I find Helm to be fairly simple to get started. For all its complexity under the hood, Helm has a gentle learning curve in my opinion. You can start deploying applications with basic
helm installcommands, then gradually learn about values, dependencies, and templating (unlucky) as they need to.Dependency management is good. Helm dependencies solve this quite elegantly, handling resolution, download and installation.
Multi-environment support lets you deploy the same chart with different configurations. It’s a good feature when you are forced to deal with multiple environments. Also, in that regard rollbacks sometimes save you.
helm rollback app 3and that’s it. You’re back at revision 3. It just works.What I don’t like
At the same time, I think Helm has fundamental design flaws that make it increasingly unsuitable for managing complex applications in modern, stratified infrastructures. First one: Go templating system. It is Helm’s biggest strength and its greatest weakness. It offers immense flexibility which is necessary for complex applications, but it results in code that is hard to reason about. The syntax is unintuitive and verbose, error messages are cryptic and unhelpful. Which value is nil? What’s the context? Why can’t I just get a proper stacktrace? It’s not rare to end up debugging templates and ending up commenting out sections and re-rendering repeatedly. This happened because I guess it was a natural choice to inherit Go templates, since they are “native”. In any case, the fundamental issue isn’t just that Go templates are bad, it’s that templating YAML is inherently problematic. It often leads to indentation bugs that break file-parsing and difficulty validating templates before rendering.
I don’t know if I am the only one, but I miss some kind of Drift detection logic. Someone manually edits a deployment and Helm has no idea. The next
helm upgrademight work, might partially fail, or might silently ignore the drift. The fact is that in complex installations with numerous microservices and dependencies, manual interventions are often necessary because Helm lacks native installation ordering. When one service fails to start while waiting for dependencies, the pragmatic solution is manual editing, but this silently breaks Helm’s understanding of your system state.Helm’s approach to secrets is “just base64 encode it and hope for the best.” Tools like Helm Secrets exist, but they feel like band-aids on a fundamental design issue.
Helm is purely client-side and imperative, even if we consider it as partially-declarative. This goes back to point 3. Helm fires commands and just trusts that what it thinks is deployed actually matches reality. Also, everything requires manual intervention. In fact, many teams end up with (imho) awkward combinations: ArgoCD + Helm, Flux + Helm, or just Helm + CI/CD. The fact that we’re retrofitting declarative behavior onto an imperative tool shows just how much the ecosystem has evolved past Helm’s original assumption.
Helm doesn’t manage an install order or readiness. Helm simply ensures the sub-charts are included in the final rendered manifests. There is absolutely no guarantee of install order or readiness. As I said in point 3 I think, you usually solve this with hacks like init containers, complex readiness probes, or by running multiple
helm installcommands in a specific order. I don’t like it.The Alternative
I don’t have an alternative as of now. Also, I don’t think there could be a better, community-supported alternative to Helm. Not because I think it’s not feasible, quite the contrary! Helm is widely used at the enterprise level and is fully supported by the CNCF, so I just believe that an alternative must be truly worthwhile to justify a change. In any case, I believe that the next step beyond Helm is a native Kubernetes system that uses CRDs, is declarative, and imposes a package structure standard similar to Linux. I hope to be able to create a proof of concept in the future :-)